Brian Vander Plaats
Developer
Blog
Developer
Over the next few months I plan on doing a bunch of research on Entity Framework, WebAPI, MVC, and AngularJS. My focus will be on how these technologies can be used to build enterprise level applications. To accomplish this I need a sample database that properly models typical enterprise entities. To this end, I’ve created a database for a fictional “Bike Store”. At the bike store, we will need to track a product catalog, inventory, customers, sales, employees, and so on. Below is a high level overview of the data needs:
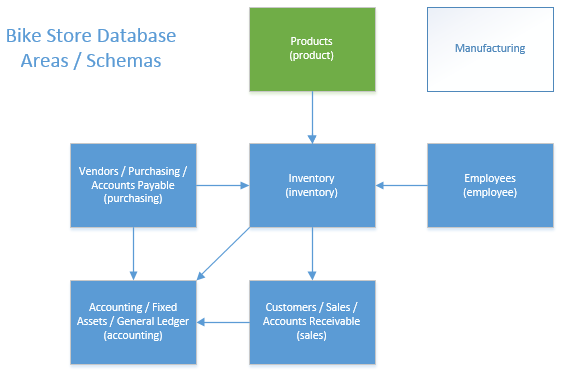
At this time I’m only implementing the Product area of the database schema, but you can see how it fits into the larger theoretical schema. This represents a fairly standard view of any enterprise. Notably we are not modeling any type of manufacturing or research entities as this is just a retail store. The detailed product schema is as follows:
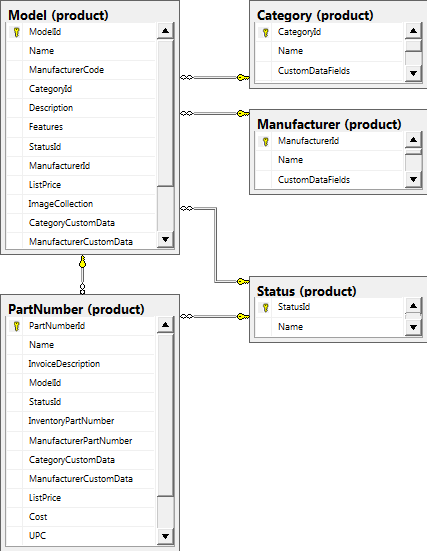
A model represents a product, and may have one or more part numbers. Coke and Coke Zero are two different models. Coke – 20 oz Bottle and Coke 12 oz can are two different part numbers of the Model – Coke. Some systems do not contain an entity for model, but represent everything at the part number level. This of course, breaks First Normal Form. In the bike store there are products that have variations on size / color, tied to detailed product information. Using the Model entity allows a common profile of product information to be shared by one or more part numbers.
A key design need is to provide a structure for storing hundreds of disparate attributes for different types of products. Simplistic systems create dozens of columns for an entity, which leads to highly sparse records, which are not efficient for storage, and requires schema changes when new attributes are needed. The next best thing is to create a key/value table relationship in the form of Model->ModelDataFieldValue->ModelDataFieldtype. This works well and I’ve done this in a number of scenarios. However for this project I’m exploring the use of JSON for this information. For each Model entity, I simply need to have a field to store the JSON data. Here I’m actually using two. One for category-specific fields, and one for model-specific fields. For example, for bicycles, I want to record the groupset, frame type, frame fit, wheelset, tires, crank dimensions, etc. This would apply to all bicycle categories. However for Trek I might want to also record if the bike is eligible for ProjectOne, or a special rebate, etc.
Ultimately the difference looks like this:
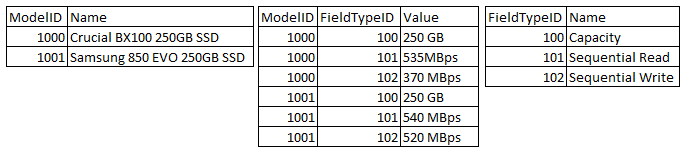
vs.
[
{"Crucial BX100 250GB SSD":{
"Capacity": "250 GB",
"Sequential Read": "535 MBps",
"Sequential Write": "370 MBps"
}
},
{"Samsung 850 EVO 250GB SSD":{
"Capacity": "250 GB",
"Sequential Read": "540 MBps",
"Sequential Write": "520 MBps"
}
}
]
(thanks to @kitroed for sending me SSD deal links while writing this post…)
Advantages to storing in JSON
Disadvantages to storing in JSON
Part Number or SKU represents the item that goes in inventory and sold to the customer. A part number is identified by the manufacturer part number or the bike store inventory part number. Most inventory systems will want to use a common / global part number scheme, since we have no control over what that manufacturer assigns in their inventory system. Note that a serial number is an instance of PartNumber at the inventory level for large items like bicycles.
ex.
Model: Gel Cork Tape
Invoice Description: Gel Cork Tape – Red
Inventory Part Number: 10500
Manufacturer Part Number: 402500
Manufacturer (or “make”) is essentially the label on the product e.g. Trek. We don’t care if Trek actually manufactures their frame, or that Bontrager is simply a label that Trek owns – at the product level these are both manufacturer’s. At the purchasing level, we may end up buying both bontrager and trek products from the same vendor/distributor.
Category includes Road Bikes, Saddles, Grip Tape, etc. Both Manufacturer and Category have JSON fields. These fields store blank sets of string/value pairs. Will be used by product entry screens to populate the related category / manufacturer specific fields that need to be filled out.
Status is also standard, but note it doesn’t contain “out-of-stock”. This is a dynamic status that should be determined by the inventory module, and could fluctuate on a daily basis, while the product is “active” the entire time.
I’ve implemented the database using Visual Studio 2015 database projects. It includes initial sample data, and can be deployed repeatedly to the same database endpoint. For the sample data, I’m using a merge approach, loading data from tab-delimited text files. This is the first time I’ve worked with database projects and overall I’m pretty happy with the tool.
I’ve deployed the current build to GitHub as brianvp/bikestore-database. As I work through my research areas I will update as needed.
Here is a technique I picked up while researching ways to generate JSON output from a CSV file. My main use case is generating sample data quickly. While JSON is easy to read and parse, I don’t feel like hand typing dozens of string/value pairs, I want to use excel like a sane person. I also do not want to upload my JSON to some random internet site. Thankfully Powershell (v3) has a built-in cmdlet that allows us to convert to JSON.
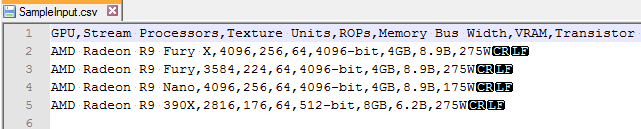
import-csv "SampleInput.csv" | ConvertTo-Json | Add-Content -Path "output.json"

which produces the following output:
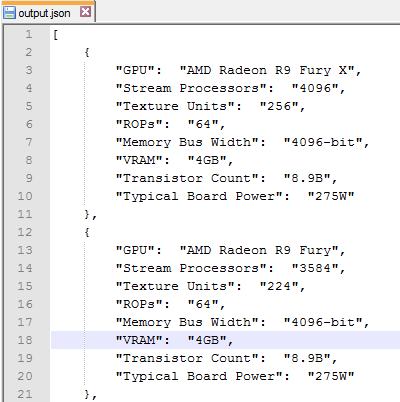
import-csv -Delimiter "`t" "SampleInput.txt" | ConvertTo-Json | Add-Content -Path "output.json"
import-csv "SampleInput.csv" | ConvertTo-Json -Compress | Add-Content -Path "output.json"
which produces the following output:

A common SQL task is to set up new tables for an application, and while you can use the GUI for this, I prefer using scripts. It’s faster, and leads to better deployment practices. (The one time I do find the designer useful is when making a column size change to a table. In this case, I will make the change in the designer, and generate a script. It looks ugly, but saves a lot of manual coding)

Since I don’t typically create tables every day, even as a dba, I like using a basic template. You can script out a template using an existing SQL Server table, which looks like this:
/****** Object: Table [product].[Category] Script Date: 10/6/2015 8:38:18 PM ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [product].[Category](
[CategoryId] [int] IDENTITY(100,1) NOT NULL,
[Name] [nvarchar](50) NULL,
[CustomDataFields] [nvarchar](max) NULL,
[DateModified] [datetime2](7) NULL,
[DateCreated] [datetime2](7) NULL DEFAULT (getdate()),
PRIMARY KEY CLUSTERED
(
[CategoryId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GO
Or if you are using SQL 2012 or later you can use code snippets:
CREATE TABLE dbo.Sample_Table
(
column_1 int NOT NULL,
column_2 int NULL
);
I don’t care for these much (too verbose or too simplistic), so I created my own:
CREATE TABLE tempdb.dbo.temp1
(
Temp1Id INT IDENTITY(1,1) NOT NULL
CONSTRAINT temp1PrimaryKey PRIMARY KEY CLUSTERED,
VALUE VARCHAR(25),
DateModified datetime2,
DateCreated datetime2 default getdate()
)
GO
CREATE TABLE tempdb.dbo.temp2
(
Temp2Id INT IDENTITY(1,1) NOT NULL
CONSTRAINT temp2PrimaryKey PRIMARY KEY CLUSTERED,
Temp1Id INT NOT NULL
CONSTRAINT Temp2Temp1ForeignKey FOREIGN KEY (Temp1Id)
REFERENCES dbo.temp1(Temp1Id),
VALUE VARCHAR(25) NULL,
DateModified datetime2,
DateCreated datetime2 default getdate()
)
GO
At my current job, I allow developers to create their own tables (following standards of course!), and a very common code review item is that they forget to make the foreign key constraint! It’s simpler to add this at the time of creation. Sometimes this makes data insertion a problem when people are “testing” – but it’s far worse to have this go uncaught when deploying to production.
Additionally, unless you are using database projects, it’s a good idea to keep all your table creation logic in a single script. This will save a lot of time when deploying to staging or production.
This list is a summary of tools I’ve used in the past year, for work or personal use.
| Visual Studio 2010 | Visual Studio 2015 |
| Linqpad | StyleCop |
| Bootstrap 2.x | Bootstrap 3 |
| AjaxControlToolkit | JQuery |
| AngularJS | SlickGrid |
| Notepad++ | Brackets |
| Chrome | Firefox ESR |
| Balsamiq Mockups | Microsoft Visio 2013 |
| Paint | Snipping Tool |
| Google Docs | Excel 2013 |
| Fogbugz (wiki) | Planning Poker |
| TortoiseHg | Fogbugz |
| Kiln | Github |
| Microsoft Outlook 2013 | Google Docs |
| Google Hangouts | HipChat |
| Skype | join.me |
| Windows 7 | Windows 8.1 |
| Server 2008 R2 | Server 2012 R2 |
| Microsoft Azure | Hyper-V (Windows 8.1) |
| VirtualBox |
| Powershell | WinMerge |
| grepWin | ProcessXP |
| ProcMon | Fiddler |
| WinDirStat | Firebug |