Brian Vander Plaats
Developer
Blog
Developer
In this article I demonstrate how to set up a Web API Service to perform simple CRUD operations. Web API is a framework within ASP.NET that allows you to create RESTful services over HTTP. The primary use case is for allowing communication from JavaScript front ends using JSON. For this example I did not include any authentication / security, which is obviously required for a production application.
As usual the full source code is up at github
Before creating a Web API Service, you should understand the principles & conventions behind REST. If you are coming from a traditional client/server background, these are not obvious, and you should take some time to understand the differences. REST, or Representational State Transfer, is not a technology, protocol, or standard, it is a software architectural pattern. It describes a way of interacting with resources through HTTP. A RESTful API is an api that adheres to the REST principles.
The key principles are:
The most important concept to understand is that when calling a service, we shouldn’t think in terms of executing some method, but that we are requesting or performing some action on a resource. For the most part, an resource is largely the same as an entity defined in Entity Framework, so if you are familiar with that you shouldn’t have too much trouble understanding this concept. This means that resources are nouns, not verbs. Customers is a resource, Orders is a resource, GetCustomerOrderHistory is *not* a resource. It’s actually two resources - one Customers, and two, order history. a RESTful path looks like this: (Note that the convention is to pluralize resource names, just like in Entity Framework. )
/api/Customers/21312/OrderHistory/
As I’ll discuss later, not everything neatly maps to a resource, and that’s OK, Pick something that makes sense, and stick with it for your application. This blog post discusses several best practices for creating RESTful services. Even if you aren’t publishing a public API, you should approach your API design with the same level of care as you would your front-end layout. Your API should not be a large collection of methods, but a carefully laid out hierarchy of resources and actions.
Setting up a Web API Project is almost identical to setting up an MVC project:
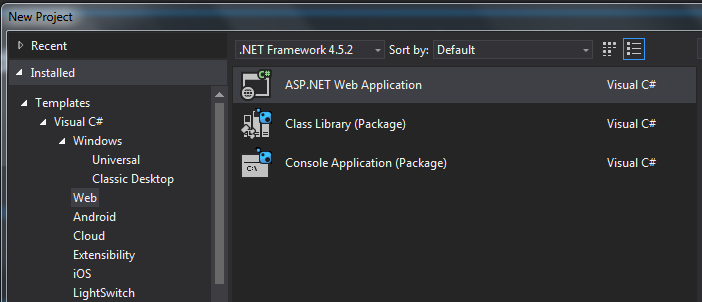
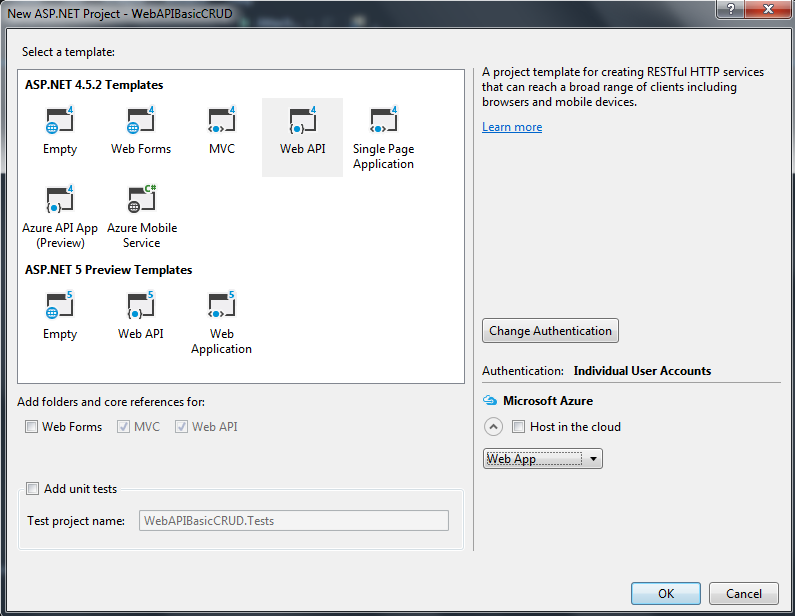
The default project templates will include an MVC Homepage, various authentication controllers, bootstrap, jquery, etc.
For this example I’m using Entity Framework Code First connected to the BikeStore database
Once you’ve created your core entities, you need to modify them slightly to work with WebAPI. If any of your entities use navigation properties, WebAPI will attempt to serialize these properties into a JSON bundle. For example our Model class has a collection of PartNumbers. When one of our WebAPI GET methods returns a model, the serializer will attempt to expand all related part numbers for a given model, which will cause a large number of database queries & processing on the web server. In most cases this is not what we want, so we have the following options:
This part is simple - the default scaffolding is very good. Right-click on the controllers folder and select Add->Controller:
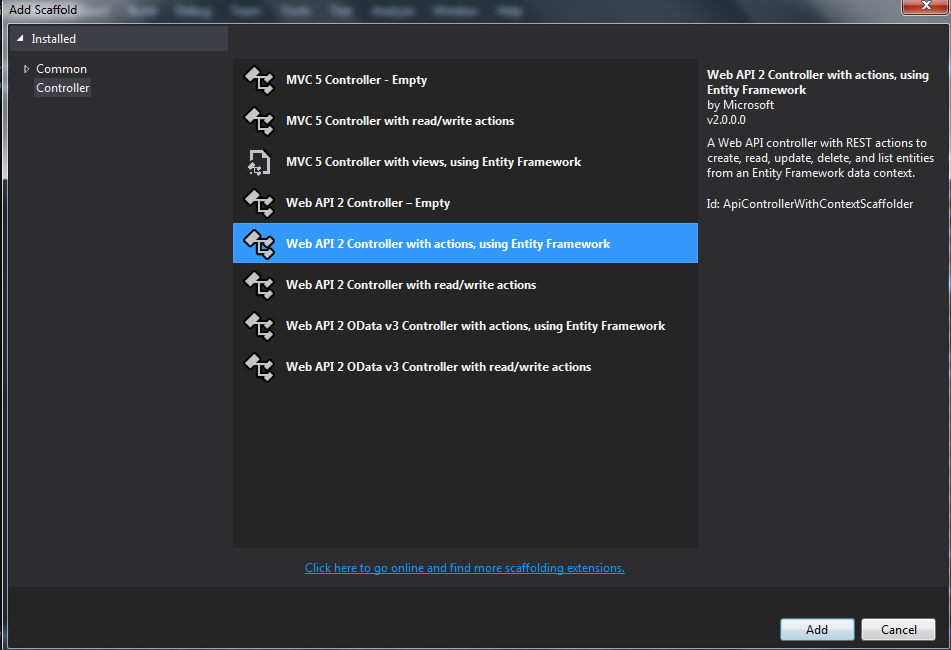
Choose the “Web API 2 Controller with actions, using Entity Framework” options
You will then need to select an entity framework class & context:
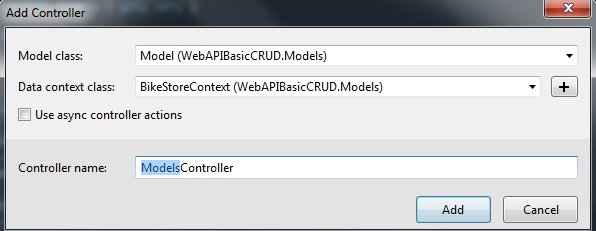
By default, the generated code almost covers every basic CRUD operation we would want to do on the model. This next section shows the code for each.
public IQueryable<Model> GetModels()
{
return db.Models;
}
// GET: api/Models/5
[ResponseType(typeof(Model))]
public IHttpActionResult GetModel(int id)
{
Model model = db.Models.Find(id);
if (model == null)
{
return NotFound();
}
return Ok(model);
}
// POST: api/Models
[ResponseType(typeof(Model))]
public IHttpActionResult PostModel(Model model)
{
if (!ModelState.IsValid)
{
return BadRequest(ModelState);
}
db.Models.Add(model);
db.SaveChanges();
return CreatedAtRoute("DefaultApi", new { id = model.ModelId }, model);
}
// PUT: api/Models/5
[ResponseType(typeof(void))]
public IHttpActionResult PutModel(int id, Model model)
{
if (!ModelState.IsValid)
{
return BadRequest(ModelState);
}
if (id != model.ModelId)
{
return BadRequest();
}
db.Entry(model).State = EntityState.Modified;
try
{
db.SaveChanges();
}
catch (DbUpdateConcurrencyException)
{
if (!ModelExists(id))
{
return NotFound();
}
else
{
throw;
}
}
return StatusCode(HttpStatusCode.NoContent);
}
// DELETE: api/Models/5
[ResponseType(typeof(Model))]
public IHttpActionResult DeleteModel(int id)
{
Model model = db.Models.Find(id);
if (model == null)
{
return NotFound();
}
db.Models.Remove(model);
db.SaveChanges();
return Ok(model);
}
To test this code, simply run the solution, and type /api/models after localhost:XXXX in the address bar. You should see a JSON result for each model in the database. Later on we will create a simple jQuery test framework to call the web methods.
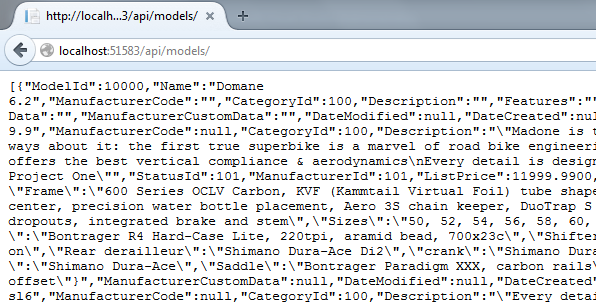
In the previous example, we saw that the /api/models path returned a JSON result. Looking at our ModelsController class, we see that this most likely called the GetModels() method, but how does this actually work?
The main reason this looks simple is the heavy use of default routing conventions and use of HTTP methods.
In WebApiConfig.cs, the standard route table is
config.Routes.MapHttpRoute(
name: "DefaultApi",
routeTemplate: "api/{controller}/{id}",
defaults: new { id = RouteParameter.Optional }
);
When a HTTP GET request is received for /api/models, this route is hit:
Ultimately /api/models maps to the GetModels() method. How does this work inside controller?
First, look for any public method starting with “Get”. Next, find a Get method that matches the Request parameters exactly. Since the calls was for /api/models and not api/models/10000, there are no parameters, so the parameterless GetModels() is executed. If the call was for api/models/10000, then the GetModel(int id) method is called.
This is very interesting as the full method name has no bearing on the action taken. We could call it GetModels(), GetSomeModels(), whatever. But we can’t call it ModelList(), and we can’t have two methods with the same list of parameters. In the first case we will get an error:
{“message”:”the requested resource does not support http method ‘GET’.”}
and the second will be an error that multiple routes are available:
{“message”:”An error has occurred.”, “ExceptionMessage”:”Multiple actions were found that match the request:…”}
It’s also interesting as the URL for getting a model and updating a model are exactly the same. The chosen controller method is based on the HTTP request method:
This is getting to be a little long, but the reason I bring this up is that for a traditional client/server developer used to simple business classes etc, this is approach is counter intuitive.
Before looking at the test framework, there is one important type of operation we need to review - searching! In our example search, we want to get back a list of part numbers by supplying one or more parameters. However, we know that the query needs to join both PartNumbers and Models, so which controller does it go in? There are two basic schools of thought here. The first way is to determine which entity is most directly related to the result set, and create a sub-resource/path. In our case, PartNumber is a reasonable choice, so we will add a custom route/method to the PartNumber controller. The second school of thought is to treat a search as a top-level resource itself. Both methods are shown below.
In both cases, I recommend using Web API attribute routing. Simply stated, attribute routing explicitly decorates controller methods for the HTTP Method and URL Path they are expected to process. For example, the paths below do not fit the standard route pattern of “api/{controller}/
/api/search/partNumber
/api/search/model
/api/partnumber/search
Rather than coming up with a new custom route pattern, you can simply add:
[Route(“api/search/partnumber”]
[HttpGet]
above SearchController.cs.PartNumberSearch()
The problem is that the standard routing expects each controller to implement one set of GET methods that are related i.e. variations on ModelSearch, not ModelSearch, PartNumberSearch, Categorysearch, etc. This could work if the search parameters are all different, but if anything that would just be a coincidence. The other approach of course is to simply create a new controller class for each type of search but that is just likely to create dozens of one-off controllers which doesn’t seem like good design…
For many types of searching there are often parameters that don’t fit the RESTful pattern of /resource/id. Fortunately, you can simply use good old query strings e.g. /resource?Param1=&Param2=&Param3= etc. One special consideration however- for your controller methods, you should always set a default value (usually null) foreach parameter. For example:
/api/search/PartNumbers?ModelName=Tape will not map to PartNumberSearch(string modelName, string partNumberName). For this to work you would need to change the URI to /api/search/PartNumbers?ModelName=Tape?PartNumberName=. You can get around this by changing the controller method to: PartNumberSearch(string modelName = null, string partNumberName = null)
/api/PartNumbers/Search?modelName=Tape
[Route("api/PartNumbers/Search")]
[ResponseType(typeof(ProductSearchResultDTO))]
public IHttpActionResult GetPartNumberSearch(string modelName = null, string partNumberName = null)
{
var query = from md in db.Models
join pn in db.PartNumbers
on md.ModelId equals pn.ModelId
join ct in db.Categories
on md.CategoryId equals ct.CategoryId
where ( md.Name.Contains(modelName)|| modelName == null ) &&
(pn.Name.Contains(partNumberName) || partNumberName == null )
select new ProductSearchResultDTO { ModelId = md.ModelId, ModelName = md.Name, PartNumberName = pn.Name, InventoryPartNumber = pn.InventoryPartNumber, ListPrice = pn.ListPrice, CategoryName = ct.Name };
return Ok(query);
}
/api/search/PartNumbers?modelName=Tape
[Route("api/Search/PartNumbers/")]
[HttpGet]
[ResponseType(typeof(ProductSearchResultDTO))]
public IHttpActionResult PartNumberSearch(string modelName = null, string partNumberName = null)
{
var query = from md in db.Models
join pn in db.PartNumbers
on md.ModelId equals pn.ModelId
join ct in db.Categories
on md.CategoryId equals ct.CategoryId
where (md.Name.Contains(modelName) || modelName == null) &&
(pn.Name.Contains(partNumberName) || partNumberName == null)
select new ProductSearchResultDTO { ModelId = md.ModelId, ModelName = md.Name, PartNumberName = pn.Name, InventoryPartNumber = pn.InventoryPartNumber, ListPrice = pn.ListPrice, CategoryName = ct.Name };
return Ok(query);
}
For this example, I’ve left both routes in the solution, but if I had to choose, I think the sub-resource works well. Most entities will need some sort of basic search, and I’d prefer to keep these in related controllers.
To test, I’ve set up a very simple jquery client that simply runs when you hit the site home page.
The code is straightforward. Note that when a resource is requested that does not exist, the HTTP return type changes from 200 to 404 not found. This is different than a traditional business/service layer that will usually return an empty or null result.
$(document).ready(function () {
//call to prevent later getJSON calls from firing before previous ones
//obviously not something to do in a production app, as this blocks
//the user from browser interaction...
$.ajaxSetup({
async:false
})
//select all Models
$.getJSON('/api/models', function (data) {
$('#console').append('All Models in the Database \r\n');
$.each(data, function (key, item) {
$('#console').append(item.ModelId + " | " + item.Name + '\r\n');
});
});
//filtered query
$.getJSON('/api/Search/PartNumbers?modelName=tape', function (data) {
$('#console').append('All Bar Tape Products in the Database \r\n');
$.each(data, function (key, item) {
$('#console').append(item.ModelId + " | " +
item.ModeName + " | " +
item.PartNumberName + " | " +
item.InventoryPartNumber + " | " +
item.ListPrice + " | " +
item.CategoryName + " | " + '\r\n');
});
});
// create a new model
var modelId = 0;
var newModel = { Name: "Domane 5.2", ListPrice: 3499.99 };
$.ajax({
type: "POST",
data: JSON.stringify(newModel),
url: "/api/models",
contentType: "application/json"
}).done(function (result) {
modelId = result.ModelId;
});
// update model
var modelToUpdate = null;
$.getJSON('/api/Models/' + modelId, function (data) {
modelToUpdate = data;
});
modelToUpdate.Features = "500 Series OCLV Frame";
$.ajax({
type: "PUT",
data: JSON.stringify(modelToUpdate),
url: "/api/models/" + modelId,
contentType: "application/json"
})
//select single model
$.getJSON('/api/models/' + modelId, function (data) {
$('#console').append('Selected Model: \r\n');
$('#console').append(data.ModelId + " | " + data.Name + '\r\n');
});
// delete model
$.ajax({
type: "DELETE",
url: "/api/models/" + modelId,
contentType: "application/json"
})
//select single model (this will be a 404 error as the model was deleted in previous operation)
$.getJSON('/api/models/' + modelId, function (data) {
$('#console').append('Selected Model: \r\n');
$('#console').append(data.ModelId + " | " + data.Name + '\r\n');
});
} );
Here is the resulting network activity:
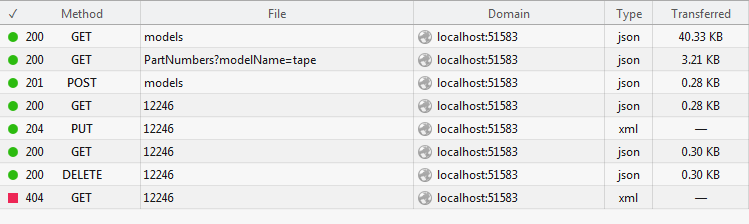
Creating a simple wrapper over entity framework classes is almost trivial in Web API. With the extra time savings not wiring up dozens of methods, you can put thought into your API organization, and how to deal with those hybrid resources that don’t strictly fit RESTful conventions…
The best thing I see about Web API is being able to take advantage of new front end-tech like AngularJS without having to re-invent your back end tools. If you are comfortable working in .NET / SQL Server, you don’t see a need to run out and learn Node.js as well. From an infrastructure perspective that’s a huge win, as deploying a Web API site is virtually no different than a web forms or MVC site.
In part 3 of this series I demonstrated using EDMX with stored procedures only. In this article I do the same with Code First. As discussed previously, while sprocs may be as far from the Code First ethos as you can get, you may find yourself in a situation where conventions and existing infrastructure require heavy use of sprocs. The example code is up at github.
The first step is to set up a new DbContext Class, and entities for your tables. Why do we want entities if we won’t be accessing tables directly? Because we will be using Stored Procedure mapping for the CUD operations. Additionally, you can re-map your sproc output class to match one of the default entities e.g. Model vs ModelSelectByKey_Result. This will be useful for the update operation later on.
You can see an example of this in part 2
Before moving on to the examples, one important caveat – currently there is no way to add new classes to an existing context using the Code First from database wizard. This is a serious drawback as EDMX has a very convenient “Update Model From Database” option.
The workaround I found, which I posted on stackoverflow, is as follows:
public virtual DbSet<TableName> TableNamePlural { get; set ; }
This doesn’t solve the problem of updating fields, but adjusting a few properties shouldn’t be too difficult
Ok so first the bad news – calling parameterized sprocs to return data with Code First is a real pain. Here’s the code for executing the ModelSelectFilter sproc:
var name = new SqlParameter("@name", DBNull.Value);
var manufacturerCode = new SqlParameter("@manufacturercode", DBNull.Value);
var categoryName = new SqlParameter("@categoryname", DBNull.Value);
var description = new SqlParameter("@description", DBNull.Value);
var features = new SqlParameter("@features", DBNull.Value);
var minListPrice = new SqlParameter("@minListPrice", DBNull.Value);
var maxListPrice = new SqlParameter("@maxListPrice", DBNull.Value);
var statusName = new SqlParameter("@statusName", DBNull.Value);
var manufacturerName = new SqlParameter("@manufacturerName", DBNull.Value);
var models = db.Database.SqlQuery<ModelSelectFilter_Result>("product.ModelSelectFilter @name, @manufacturercode, @categoryname,@description,@features,@minListPrice,@maxListPrice,@statusName, @manufacturerName",
name,manufacturerCode, categoryName, description, features, minListPrice,maxListPrice,statusName,manufacturerName).ToList();
compared to the same sproc using function mapping in EDMX:
var models = db.ModelSelectFilter(null,null,null,null,null,null,null,null,null);
Yikes. At this point there doesn’t seem to be much difference in using raw ado.net calls or some micro ORM such as Dapper, which would look something like this:
var models = cnn.Query<Model>("product.ModelSelectFilter", new {name = null, manufacturerCode = null, categoryName = null, description = null, features = null, minListPrice = null, maxListPrice = null, statusName=null,manufacturerName=null }, commandType:CommandType.StoredProcedure ).ToList();
Thankfully stored procedure mapping takes some of the pain out of this.
Stored procedure mapping allows us perform data operations on entities as if entity framework were generating the SQL itself. Mapping the CUD operations takes place in the OnModelCreating() method of the dbContext class. For each entity you wish to map to, call the MapToStoredProcedures() method:
modelBuilder.Entity<Model>()
.MapToStoredProcedures(s =>
s.Update(u => u.HasName("product.ModelUpdate"))
.Delete( d => d.HasName("product.ModelDelete"))
.Insert( i => i.HasName("product.ModelInsert"))
);
Note if your sprocs use output parameters they will need to have a default value of null, and won’t be accessible through procedure mapping.
Adding a model is very simple, and no different from direct table access, which is what we want:
var model = new Model { Name = "Domane 5.2", ListPrice = 3499.99m };
db.Models.Add(model);
db.SaveChanges();
modelId = model.ModelId;
Updating has some caveats, but not too bad. First, you will need to load an instance of the entity, which you can do by changing the type of SqlQuery to
var modelIdParam = new SqlParameter("@modelid", modelId);
var model = db.Database.SqlQuery<Model>("product.ModelSelectByKey @modelid", modelIdParam).SingleOrDefault();
if (model != null)
{
db.Models.Attach(model);
model.Features = "500 Series OCLV Frame";
db.SaveChanges();
}
Second, note that the new model will not be part of the db.Models collection. If you update one or more fields and call db.SaveChanges(), nothing will happen. You first need to attach the model to the Models collection. This is a slight difference from EDMX where you can set the function import to map a collection of Models, which the context will automatically detect changes to.
Nothing complicated here again:
var model = new Model { ModelId = modelId };
db.Models.Attach(model);
db.Models.Remove(model);
db.SaveChanges();
Below is the full SQL Profiler trace of the test program:
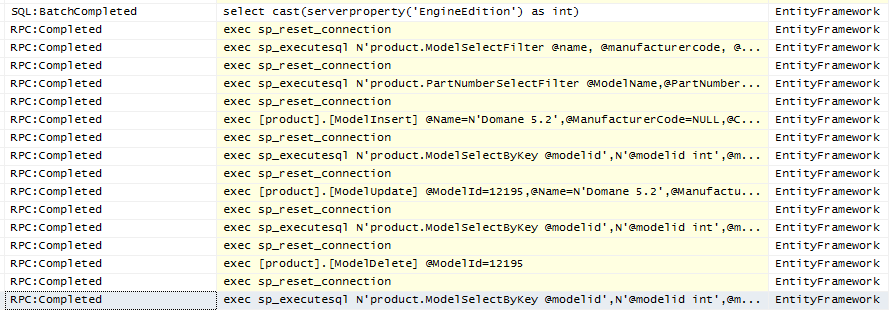
So there you have it, a full set of CRUD operations in Code First using only sprocs. After looking at both, my conclusion that if you use sprocs extensively or exclusively, Code First is not the right tool. But if you were using a Code First in the majority of your application, I would not create an edmx file simply to interface with a handful of sprocs, Code First certainly can work with sprocs that interact with entities.
In part I of this series, I created a simple entity data model to demonstrate basic CRUD operations. I now continue this demonstration using stored procedures exclusively. Before going into these examples, I’d like to first discuss why one would want to use stored procedures.
First, I think most developers would agree that a mixture of sprocs and direct table mapping via an ORM is a good approach. There are simply some types of queries that are more efficient when you craft the SQL directly. But many queries are quite straightforward, and using an ORM can save a lot of time (both in writing and later deployment). As I’ve found out, both EDMX and Code First do a decent job allowing access to sprocs. However, I’m talking about using sprocs exclusively. That is the current technique my company is using, and I suspect a significant number of others companies are using as well.
Here are a few reasons why I feel this is a valid approach:
I do not however subscribe to the following arguments:
Now, I’d be happy to discuss the merits of these with any developer and I’m not claiming that direct table access is bad universally. My chief concern is this: If a data access technique (namely data access through sprocs) is widely accepted and/or has a large legacy codebase, then it should be supported by Microsoft’s current flavor of data access tech. I’m actually considering going the direct-table approach for some future apps, and knowing that I can still make use of existing sproc infrastructure is crucial.
So how well does Entity Framework support sprocs? “it depends”. In my research, EF 6 / EDMX has good support for sprocs, and Code First sprocs sort of work (which I will go into in a future post).
When thinking about how an ORM should interact with sprocs, we want to see the following happen, and EF more or less supports these:
The rest of this post details how this works with EDMX. As usual, the source is on github
The primary way edmx interacts with sprocs is through “function imports”, and it is very easy to add these to a new or existing data model. When in the wizard, you simply choose the sprocs you need (and you can easily add more in the future by running the Update Data Model from Database wizard):
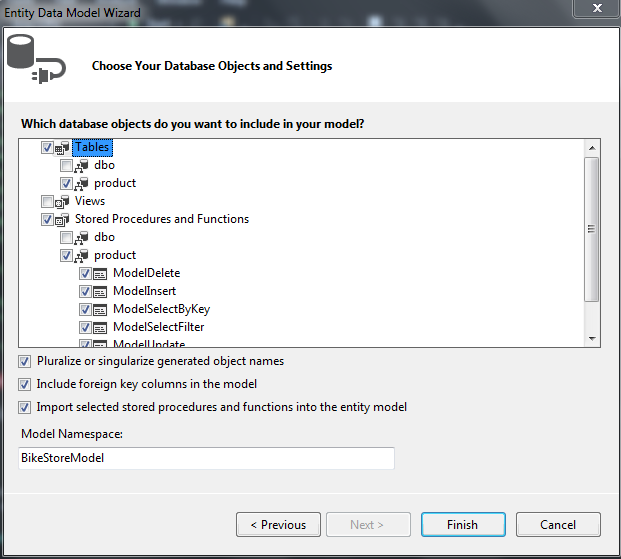
For each sproc selected, a function import reference is added in the data model. You can access this function by simply calling
db.ModelSelectByKey(modelId)
If the sproc returns a resultset, a new POCO class is added to the model as well, with a name of
public partial class ModelSelectByKey_Result
{
public int ModelId { get; set; }
public string Name { get; set; }
public string ManufacturerCode { get; set; }
...
}
Putting this together in our sample program, here is a simple sproc call:
using (var db = new BikeStoreEntities())
{
var models = db.ModelSelectFilter(null,null,null,null,null,null,null,null,null);
foreach (var model in models)
{
Console.WriteLine(model.ModelId + " | " + model.Name);
}
}
you can view the current list of function imports through the model browser:
While calling functions works well, this doesn’t make use of the primary advantage of EF – working with entities. We want to load a model, update it, create a new model, delete, from a “Model” class, not just call a bunch of functions with parameters. This is accomplished through “CUD” mapping. You cannot map the “Read” operation, which is odd because as you’ll see in a moment, it is trivial to populate a list of Model entities directly from a sproc… For the other three operations, you simply select the entity in the model diagram, and choose the “stored procedure mapping”. From there you can provide an Insert, Delete, and Update sproc.
Here’s what each looks like for the Model entity
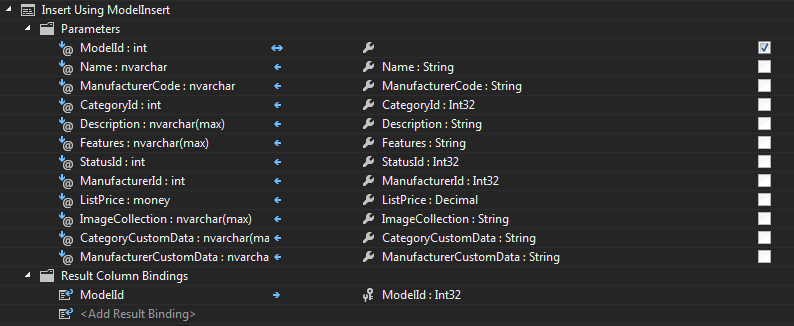
Note you must provide a rows affected output for an identity column (ModelId) if you want to access this after insert.
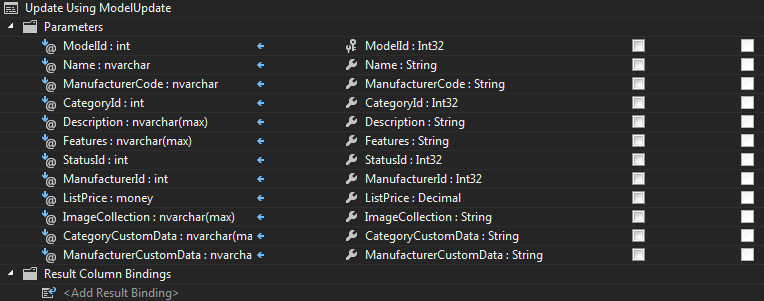

The sprocs will be utilized when you invoke the SaveChanges() method of the context. Note that mapping is an all or nothing approach. You can’t use an insert sproc and then direct table access for updates – you need to provide both an insert and update sproc. However, you do not need to provide the sproc if your code avoids that particular option i.e. you can omit the delete sproc if you never call delete on the model.
Below is the code for creating a new Model, and it looks no different from the standard direct table access of EF:
int modelId = 0;
using (var db = new BikeStoreEntities())
{
var model = new Model { Name = "Domane 5.2", ListPrice = 3499.99m };
db.Models.Add(model);
db.SaveChanges();
modelId = model.ModelId;
}
Console.WriteLine("New Model: " + modelId);
Notice that ModelInsert has an output parameter, which isn’t supported by EF very well. While I was able to get this sproc working while retaining the output parameter, I wasn’t able to determine how to extract the result after SaveChanges(), so I decided to simply change the ModelInsert sproc to follow the pattern of selecting the ID after insert (which is how EF would generate the T-SQL). The happy result is that EF is able to map this to the ModelId property, so as long as you are willing to make that change, this is good.
using (var db = new BikeStoreEntities())
{
var model = db.ModelSelectByKey(modelId).FirstOrDefault();
if (model != null)
{
Model m = new Model();
m.ModelId = model.ModelId;
m.Name = model.Name;
m.ManufacturerCode = model.ManufacturerCode;
m.CategoryId = model.CategoryId;
m.Description = model.Description;
m.Features = model.Features;
m.StatusId = model.StatusId;
m.ManufacturerId = model.ManufacturerId;
m.ListPrice = model.ListPrice;
m.ImageCollection = model.ImageCollection;
m.CategoryCustomData = model.CategoryCustomData;
m.ManufacturerCustomData = model.ManufacturerCustomData;
db.Models.Attach(m);
// make the change - needs to happen after the attach, otherwise the change
// will not be registered
m.Features = "500 Series OCLV Frame";
db.SaveChanges();
}
}
Above was my first attempt at writing an update sequence, and you can see this is not an efficient solution. Who wants to write out all those extra mapping lines? Not to mention when fields change… The solution is to change the ModelSelectByKey Function Import from using a complex return type of ModelSelectByKey_Result to a collection of Model entities
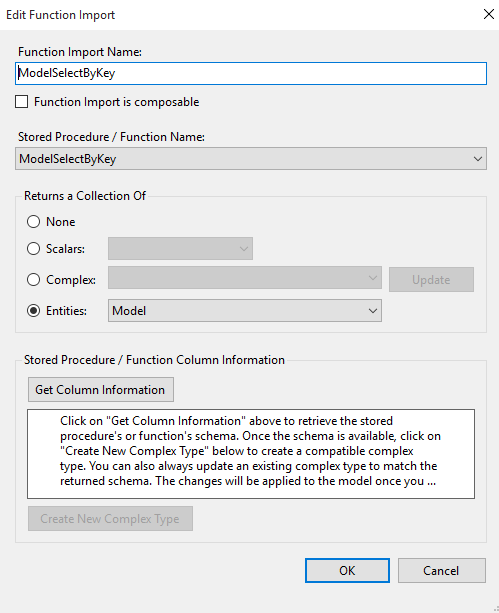
Now we can simplify the code to this:
using (var db = new BikeStoreEntities())
{
var model = db.ModelSelectByKey(modelId).FirstOrDefault();
if (model != null)
{
model.Features = "500 Series OCLV Frame";
db.SaveChanges();
}
}
The only problem with this is if your sproc contains additional fields not part of the Model entity, they won’t be accessible.
using (var db = new BikeStoreEntities())
{
// uses sprocs when mapping set in model
var model = new Model { ModelId = modelId };
db.Models.Attach(model);
db.Models.Remove(model);
db.SaveChanges();
}
Not much to see here, works as expected. At this point we’ve replicated all of the key CRUD operations in the earlier examples. Below is a trace of the entire application running in SQLProfiler:
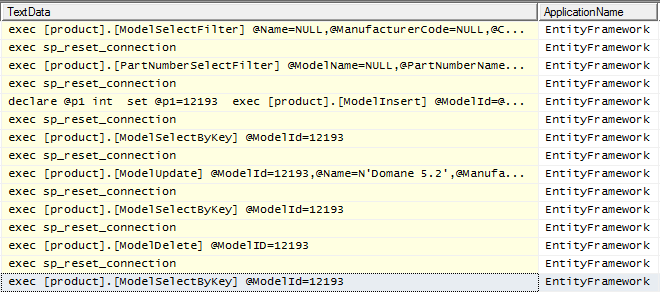
Before wrapping up, let’s talk about direct sproc calls. In the example below, instead of using a function import, we can call the SqlQuery() method and pass the name of the sproc as well as any necessary parameters:
using (var db = new BikeStoreEntities())
{
var name = new SqlParameter("@name", DBNull.Value);
var manufacturerCode = new SqlParameter("@manufacturercode", DBNull.Value);
var categoryName = new SqlParameter("@categoryname", DBNull.Value);
var description = new SqlParameter("@description", DBNull.Value);
var features = new SqlParameter("@features", DBNull.Value);
var minListPrice = new SqlParameter("@minListPrice", DBNull.Value);
var maxListPrice = new SqlParameter("@maxListPrice", DBNull.Value);
var statusName = new SqlParameter("@statusName", DBNull.Value);
var manufacturerName = new SqlParameter("@manufacturerName", DBNull.Value);
var models = db.Database.SqlQuery<ModelSelectFilter_Result>("product.ModelSelectFilter @name, @manufacturercode, @categoryname,@description,@features,@minListPrice,@maxListPrice,@statusName, @manufacturerName",
name,manufacturerCode, categoryName, description, features, minListPrice,maxListPrice,statusName,manufacturerName).ToList();
foreach (var model in models)
{
Console.WriteLine(model.ModelId + " | " + model.Name);
}
}
Not a very efficient technique, especially when using a number of parameters. At this point you are simply using EF as a wrapper for ADO.NET, so if this is your main technique, why bother using EF at all?
All in all, sproc access in EDMX is not that bad, and lets us work with entities to a large degree. If your apps are stored procedure-centric, there is a lot of built-in support in Entity Framework that you should find useful.
The second part of my Entity Framework series is identical to the first, except this time I’m using Code First. I’m not going to go into as much detail, but will show the differences. As usual the code is hosted on github.
With Code First, there is no .edmx file, just a DbContext class and a set of POCO classes. You will use the DbContext to load the POCO classes from the database. Note that you should name your model
You’ll then select Code First from database:
And choose your objects: (note that Stored Procedures and Functions are not available options)
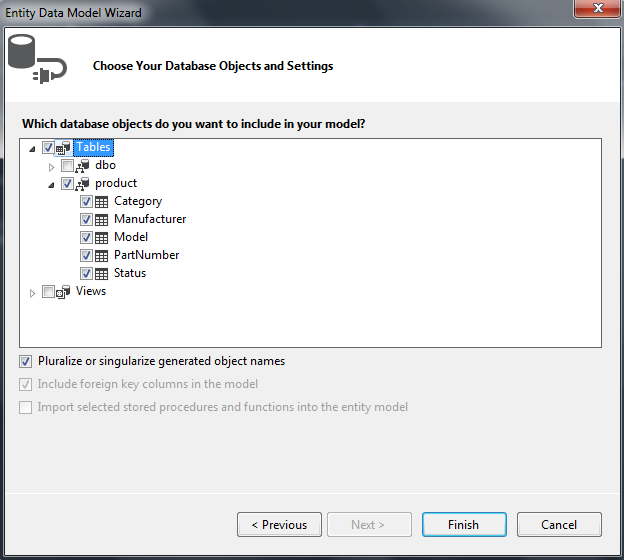
After you finish the wizard, your project tree will look as follows: (you should probably put these into a sub folder e.g. \models)
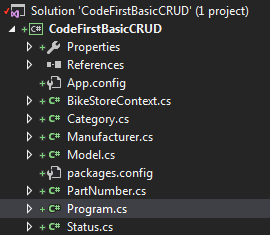
From here the code is almost identical to the edmx version, with a few key differences. First, instead of:
using (var db = new BikeStoreEntities())
{
//do database stuff
}
You call this:
using (var db = new BikeStoreContext())
{
//do database stuff
}
Second, while the SQL executed is virtually identical, the first time the context is accessed, the following SQL executes:
IF db_id(N'BikeStore') IS NOT NULL SELECT 1 ELSE SELECT Count(*) FROM sys.databases WHERE [name]=N'BikeStore'
SELECT Count(*)
FROM INFORMATION_SCHEMA.TABLES AS t
WHERE t.TABLE_SCHEMA + '.' + t.TABLE_NAME IN ('product.Category','product.Model','product.Manufacturer','product.PartNumber','product.Status')
OR t.TABLE_NAME = 'EdmMetadata'
exec sp_executesql N'SELECT
[GroupBy1].[A1] AS [C1]
FROM ( SELECT
COUNT(1) AS [A1]
FROM [dbo].[__MigrationHistory] AS [Extent1]
WHERE [Extent1].[ContextKey] = @p__linq__0
) AS [GroupBy1]',N'@p__linq__0 nvarchar(4000)',@p__linq__0=N'CodeFirstBasicCRUD.BikeStoreContext'
SELECT
[GroupBy1].[A1] AS [C1]
FROM ( SELECT
COUNT(1) AS [A1]
FROM [dbo].[__MigrationHistory] AS [Extent1]
) AS [GroupBy1]
SELECT TOP (1)
[Extent1].[Id] AS [Id],
[Extent1].[ModelHash] AS [ModelHash]
FROM [dbo].[EdmMetadata] AS [Extent1]
ORDER BY [Extent1].[Id] DESC
These SQL calls were not present in any of the edmx traces – these are support for Code First Migrations. We can turn this off in the constructor of our context class:
public BikeStoreContext()
: base("name=BikeStoreContext")
{
Database.SetInitializer<BikeStoreContext>(null);
}
At this point we have two approaches that achieve the same basic goal, but the basic question is why are there two approaches? Apparently Microsoft feels this is a bad idea, so in EF 7 the emdx approach is being dropped. Although it’s still early in my investigation, Code First feels cleaner, and I certainly have no love for large xml-based designer files.
As a first of a multi-part series, I am exploring Entity Framework 6.X. My goal is to begin with simple examples, working up to using Entity Framework in a production app. I will explore both the designer/EDMX style, as well as CodeFirst, using Visual Studio 2015. In all cases, I will be focusing on an existing database – the Bike Store database. Apparently the next version of Entity Framework, EF 7, will not include the EDMX/designer option. Because of this, I seriously considered ignoring EDMX all together and focusing on CodeFirst, however A) Microsoft will support EF 6 for many years yet and B) I want to understand the problems EDMX is trying to solve, and see if CodeFirst is a sufficient replacement.
For this first post, we will look at simple CRUD operations using an EDMX model. You can see the full code on github.
The simplest approach to demonstrate EDMX is using a console application. After creating the project, you’ll need to add a new ADO.Net Entity Data Model:
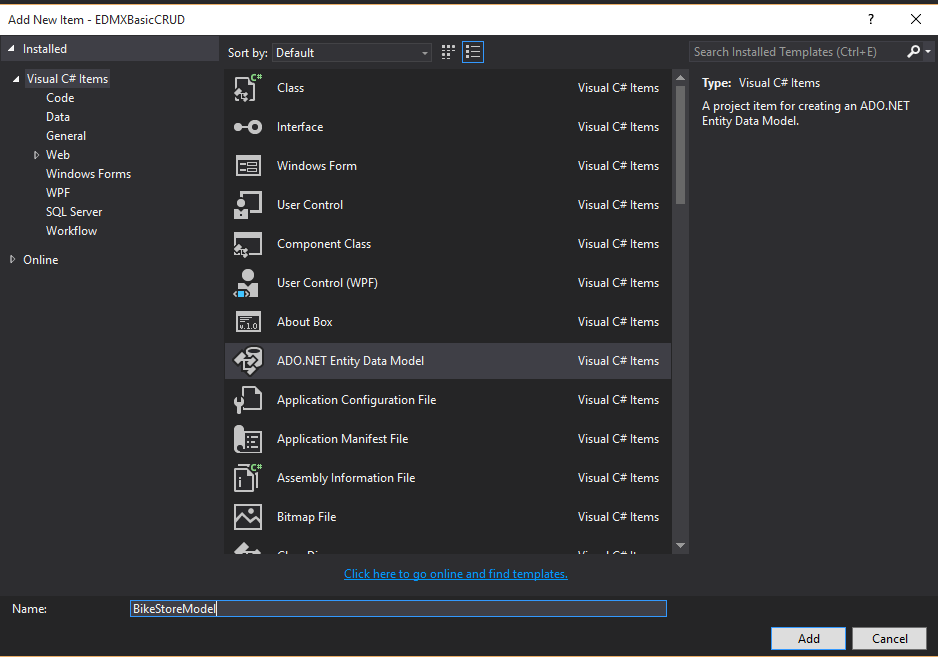
Choose the EF Designer From database option:
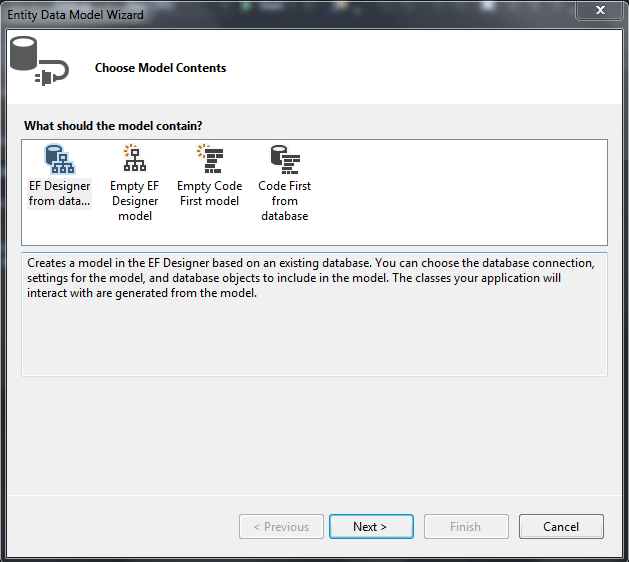
Then choose which tables to bring over (you can add views and sprocs as well – I will cover this in a future post).
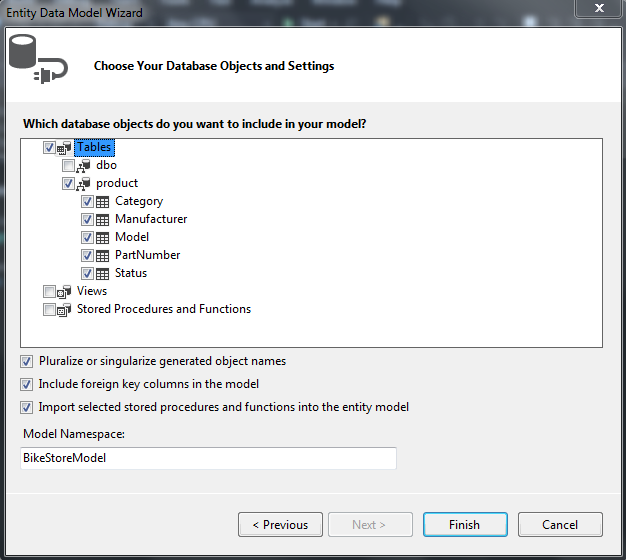
Select version 6.X:
With the wizard completed, your project will contain a new .edmx file and a sub-tree containing the POCO classes, context class, templates, and designer files:
Opening the edmx designer, the tables look as follows (after manual positioning):
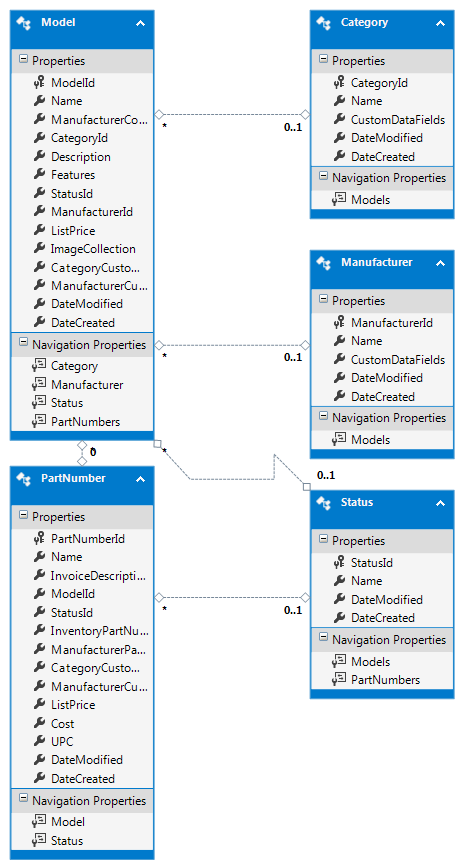
In solution explorer, if you select the edmx file, a new tab appears that displays a sub-tree of model contents (note this is where sprocs can be added to the model)
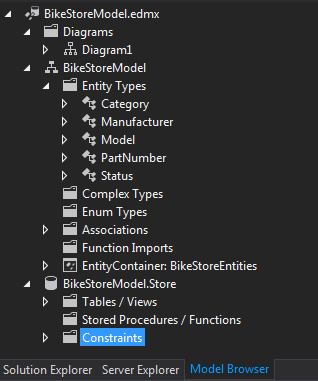
The first step to using the new entities is to create a database context object. I recommend sticking to the standard practice of wrapping the call in a using block:
using (var db = new BikeStoreEntities())
{
//do database stuff
}
The rest of this post will demonstrate six common data usage patterns:
In addition to the c# code, I will post the generated SQL Profiler trace. (I will write a future post on SQL profiler, but suffice it to say, if you do any serious data work, you need to be using this tool!)
using (var db = new BikeStoreEntities())
{
var query = from m in db.Models
orderby m.Name
select m;
Console.WriteLine("All Models in the Database");
foreach (var model in query)
{
Console.WriteLine(model.ModelId + " | " + model.Name);
}
}
SELECT
[Extent1].[ModelId] AS [ModelId],
[Extent1].[Name] AS [Name],
[Extent1].[ManufacturerCode] AS [ManufacturerCode],
[Extent1].[CategoryId] AS [CategoryId],
[Extent1].[Description] AS [Description],
[Extent1].[Features] AS [Features],
[Extent1].[StatusId] AS [StatusId],
[Extent1].[ManufacturerId] AS [ManufacturerId],
[Extent1].[ListPrice] AS [ListPrice],
[Extent1].[ImageCollection] AS [ImageCollection],
[Extent1].[CategoryCustomData] AS [CategoryCustomData],
[Extent1].[ManufacturerCustomData] AS [ManufacturerCustomData],
[Extent1].[DateModified] AS [DateModified],
[Extent1].[DateCreated] AS [DateCreated]
FROM [product].[Model] AS [Extent1]
ORDER BY [Extent1].[Name] ASC
Note that the SQL above is not executed until the query is accessed in the foreach block. This is known as deferred execution. After execution, the result set is kept in memory for further iterations through the loop.
A common SQL pattern is joining multiple tables into a custom result set. Native SQL Code is tough to beat here, but we’ll see how Entity Framework does:
using (var db = new BikeStoreEntities())
{
var query = from md in db.Models
join pn in db.PartNumbers
on md.ModelId equals pn.ModelId
join ct in db.Categories
on md.CategoryId equals ct.CategoryId
where md.Name.Contains("tape")
select new { md.ModelId, ModelName = md.Name, PartNumberName = pn.Name, pn.InventoryPartNumber, pn.ListPrice, CategoryName = ct.Name };
Console.WriteLine("All Bar Tape Products in the Database");
foreach (var item in query)
{
Console.WriteLine(item.ModelId + " | " + item.ModelName + " | " + item.PartNumberName + " | " + item.InventoryPartNumber + " | " + item.ListPrice + " | " + item.CategoryName);
}
}
SELECT
[Extent1].[ModelId] AS [ModelId],
[Extent1].[Name] AS [Name],
[Extent2].[Name] AS [Name1],
[Extent2].[InventoryPartNumber] AS [InventoryPartNumber],
[Extent2].[ListPrice] AS [ListPrice],
[Extent3].[Name] AS [Name2]
FROM [product].[Model] AS [Extent1]
INNER JOIN [product].[PartNumber] AS [Extent2] ON [Extent1].[ModelId] = [Extent2].[ModelId]
INNER JOIN [product].[Category] AS [Extent3] ON [Extent1].[CategoryId] = [Extent3].[CategoryId]
WHERE [Extent1].[Name] LIKE N'%tape%'
Not too bad – the linq code is very similar to the generated SQL Code.
using (var db = new BikeStoreEntities())
{
var model = new Model { Name = "Domane 5.2", ListPrice = 3499.99m };
db.Models.Add(model);
db.SaveChanges();
modelId = model.ModelId;
}
exec sp_executesql N'INSERT [product].[Model]([Name], [ManufacturerCode], [CategoryId], [Description], [Features], [StatusId], [ManufacturerId], [ListPrice], [ImageCollection], [CategoryCustomData], [ManufacturerCustomData], [DateModified], [DateCreated])
VALUES (@0, NULL, NULL, NULL, NULL, NULL, NULL, @1, NULL, NULL, NULL, NULL, NULL)
SELECT [ModelId]
FROM [product].[Model]
WHERE @@ROWCOUNT > 0 AND [ModelId] = scope_identity()',N'@0 nvarchar(100),@1 decimal(19,4)',@0=N'Domane 5.2',@1=3499.9900
Notice the select immediately following the insert operation. Scope_Identity() retrieves the identity value of ModelId for the inserted row. Entity Framework then maps this into the ModelId property of the model reference we added.
using (var db = new BikeStoreEntities())
{
var model = db.Models.SingleOrDefault(b => b.ModelId == modelId);
Console.WriteLine("Selected Model:");
if ( model != null)
{
Console.WriteLine(model.ModelId + " | " + model.Name);
}
}
exec sp_executesql N'SELECT TOP (2)
[Extent1].[ModelId] AS [ModelId],
[Extent1].[Name] AS [Name],
[Extent1].[ManufacturerCode] AS [ManufacturerCode],
[Extent1].[CategoryId] AS [CategoryId],
[Extent1].[Description] AS [Description],
[Extent1].[Features] AS [Features],
[Extent1].[StatusId] AS [StatusId],
[Extent1].[ManufacturerId] AS [ManufacturerId],
[Extent1].[ListPrice] AS [ListPrice],
[Extent1].[ImageCollection] AS [ImageCollection],
[Extent1].[CategoryCustomData] AS [CategoryCustomData],
[Extent1].[ManufacturerCustomData] AS [ManufacturerCustomData],
[Extent1].[DateModified] AS [DateModified],
[Extent1].[DateCreated] AS [DateCreated]
FROM [product].[Model] AS [Extent1]
WHERE [Extent1].[ModelId] = @p__linq__0',N'@p__linq__0 int',@p__linq__0=11043
using (var db = new BikeStoreEntities())
{
var model = db.Models.SingleOrDefault(b =>; b.ModelId == modelId);
if (model != null)
{
model.Features = "500 Series OCLV Frame";
db.SaveChanges();
}
}
(excluding SQL generated by SingleOrDefault()
exec sp_executesql N'UPDATE [product].[Model]
SET [Features] = @0
WHERE ([ModelId] = @1)
',N'@0 nvarchar(max) ,@1 int',@0=N'500 Series OCLV Frame',@1=11043
This is quite interesting – the update statement generates a custom list of update fields based on the state of the model. Definitely a situation where auto generation of SQL is useful. Also note that no update statement(s) are sent to SQL Server until db.SaveChanges() is called.
using (var db = new BikeStoreEntities())
{
var model = new Model { ModelId = modelId };
db.Models.Attach(model);
db.Models.Remove(model);
db.SaveChanges();
}
Many examples have you populate an entity via single select before deleting, but the above approach does generate a select statement before deleting.
exec sp_executesql N'DELETE [product].[Model]
WHERE ([ModelId] = @0)',N'@0 int',@0=11043
These examples demonstrate basic access to a SQL Database through Entity Framework. So far I am impressed with the SQL generation capabilities. The generated SQL is basically the same as I would write if I were writing the SQL manually. A key benefit to writing SQL is using SSMS and testing queries immediately. While this isn’t as easy in Visual Studio, I recommend LINQPad for this purpose. It even pluralizes the entity / table names for you! (category table in database referenced as categories in LINQ)