In part I of this series, I created a simple entity data model to demonstrate basic CRUD operations. I now continue this demonstration using stored procedures exclusively. Before going into these examples, I’d like to first discuss why one would want to use stored procedures.
Why use Stored Procedures?
First, I think most developers would agree that a mixture of sprocs and direct table mapping via an ORM is a good approach. There are simply some types of queries that are more efficient when you craft the SQL directly. But many queries are quite straightforward, and using an ORM can save a lot of time (both in writing and later deployment). As I’ve found out, both EDMX and Code First do a decent job allowing access to sprocs. However, I’m talking about using sprocs exclusively. That is the current technique my company is using, and I suspect a significant number of others companies are using as well.
Here are a few reasons why I feel this is a valid approach:
I do not however subscribe to the following arguments:
Now, I’d be happy to discuss the merits of these with any developer and I’m not claiming that direct table access is bad universally. My chief concern is this: If a data access technique (namely data access through sprocs) is widely accepted and/or has a large legacy codebase, then it should be supported by Microsoft’s current flavor of data access tech. I’m actually considering going the direct-table approach for some future apps, and knowing that I can still make use of existing sproc infrastructure is crucial.
Entity Framework and Sprocs
So how well does Entity Framework support sprocs? “it depends”. In my research, EF 6 / EDMX has good support for sprocs, and Code First sprocs sort of work (which I will go into in a future post).
When thinking about how an ORM should interact with sprocs, we want to see the following happen, and EF more or less supports these:
The rest of this post details how this works with EDMX. As usual, the source is on github
Function Imports
The primary way edmx interacts with sprocs is through “function imports”, and it is very easy to add these to a new or existing data model. When in the wizard, you simply choose the sprocs you need (and you can easily add more in the future by running the Update Data Model from Database wizard):
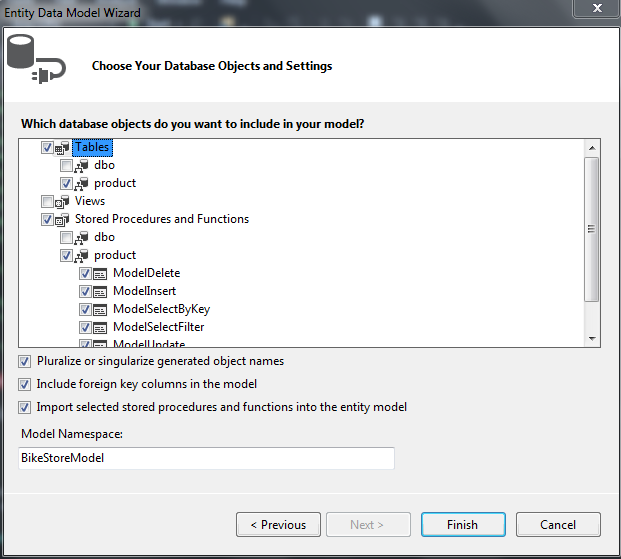
For each sproc selected, a function import reference is added in the data model. You can access this function by simply calling
db.ModelSelectByKey(modelId)
If the sproc returns a resultset, a new POCO class is added to the model as well, with a name of
public partial class ModelSelectByKey_Result
{
public int ModelId { get; set; }
public string Name { get; set; }
public string ManufacturerCode { get; set; }
...
}
Putting this together in our sample program, here is a simple sproc call:
using (var db = new BikeStoreEntities())
{
var models = db.ModelSelectFilter(null,null,null,null,null,null,null,null,null);
foreach (var model in models)
{
Console.WriteLine(model.ModelId + " | " + model.Name);
}
}
you can view the current list of function imports through the model browser:
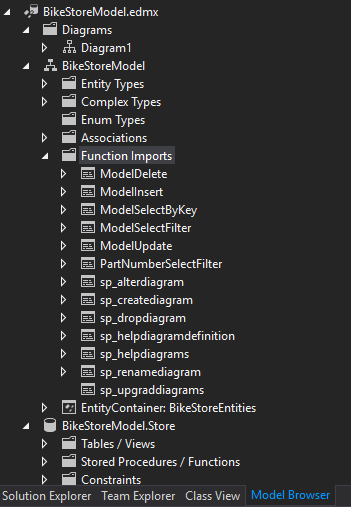
Stored Procedure Mapping
While calling functions works well, this doesn’t make use of the primary advantage of EF – working with entities. We want to load a model, update it, create a new model, delete, from a “Model” class, not just call a bunch of functions with parameters. This is accomplished through “CUD” mapping. You cannot map the “Read” operation, which is odd because as you’ll see in a moment, it is trivial to populate a list of Model entities directly from a sproc… For the other three operations, you simply select the entity in the model diagram, and choose the “stored procedure mapping”. From there you can provide an Insert, Delete, and Update sproc.
Here’s what each looks like for the Model entity
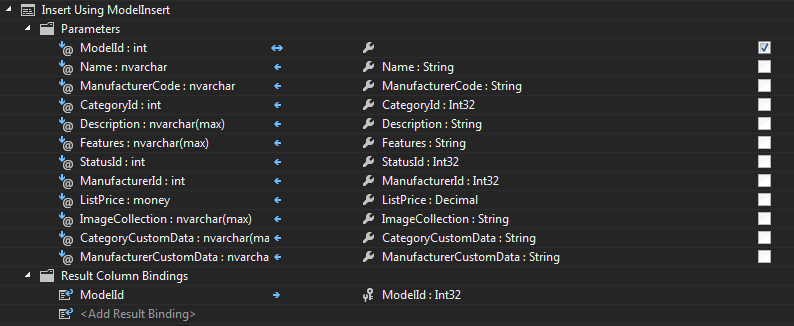
Note you must provide a rows affected output for an identity column (ModelId) if you want to access this after insert.
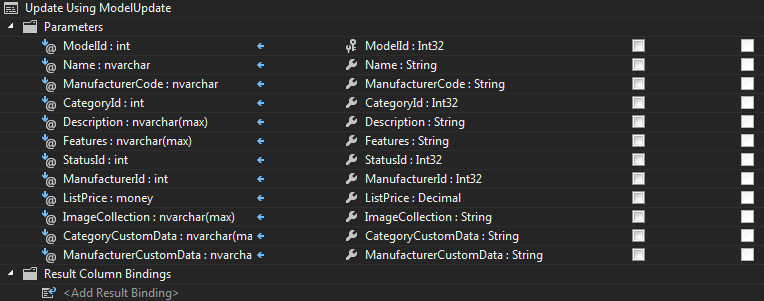

The sprocs will be utilized when you invoke the SaveChanges() method of the context. Note that mapping is an all or nothing approach. You can’t use an insert sproc and then direct table access for updates – you need to provide both an insert and update sproc. However, you do not need to provide the sproc if your code avoids that particular option i.e. you can omit the delete sproc if you never call delete on the model.
Create
Below is the code for creating a new Model, and it looks no different from the standard direct table access of EF:
int modelId = 0;
using (var db = new BikeStoreEntities())
{
var model = new Model { Name = "Domane 5.2", ListPrice = 3499.99m };
db.Models.Add(model);
db.SaveChanges();
modelId = model.ModelId;
}
Console.WriteLine("New Model: " + modelId);
Notice that ModelInsert has an output parameter, which isn’t supported by EF very well. While I was able to get this sproc working while retaining the output parameter, I wasn’t able to determine how to extract the result after SaveChanges(), so I decided to simply change the ModelInsert sproc to follow the pattern of selecting the ID after insert (which is how EF would generate the T-SQL). The happy result is that EF is able to map this to the ModelId property, so as long as you are willing to make that change, this is good.
Update
using (var db = new BikeStoreEntities())
{
var model = db.ModelSelectByKey(modelId).FirstOrDefault();
if (model != null)
{
Model m = new Model();
m.ModelId = model.ModelId;
m.Name = model.Name;
m.ManufacturerCode = model.ManufacturerCode;
m.CategoryId = model.CategoryId;
m.Description = model.Description;
m.Features = model.Features;
m.StatusId = model.StatusId;
m.ManufacturerId = model.ManufacturerId;
m.ListPrice = model.ListPrice;
m.ImageCollection = model.ImageCollection;
m.CategoryCustomData = model.CategoryCustomData;
m.ManufacturerCustomData = model.ManufacturerCustomData;
db.Models.Attach(m);
// make the change - needs to happen after the attach, otherwise the change
// will not be registered
m.Features = "500 Series OCLV Frame";
db.SaveChanges();
}
}
Above was my first attempt at writing an update sequence, and you can see this is not an efficient solution. Who wants to write out all those extra mapping lines? Not to mention when fields change… The solution is to change the ModelSelectByKey Function Import from using a complex return type of ModelSelectByKey_Result to a collection of Model entities
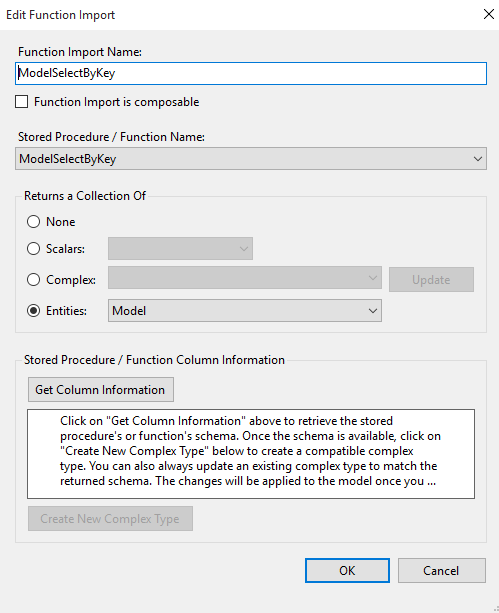
Now we can simplify the code to this:
using (var db = new BikeStoreEntities())
{
var model = db.ModelSelectByKey(modelId).FirstOrDefault();
if (model != null)
{
model.Features = "500 Series OCLV Frame";
db.SaveChanges();
}
}
The only problem with this is if your sproc contains additional fields not part of the Model entity, they won’t be accessible.
Delete
using (var db = new BikeStoreEntities())
{
// uses sprocs when mapping set in model
var model = new Model { ModelId = modelId };
db.Models.Attach(model);
db.Models.Remove(model);
db.SaveChanges();
}
Not much to see here, works as expected. At this point we’ve replicated all of the key CRUD operations in the earlier examples. Below is a trace of the entire application running in SQLProfiler:
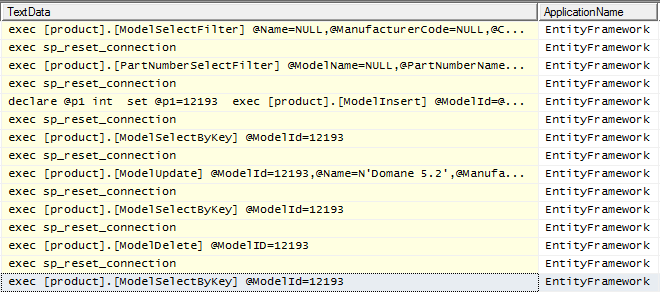
Direct Procedure Calls
Before wrapping up, let’s talk about direct sproc calls. In the example below, instead of using a function import, we can call the SqlQuery() method and pass the name of the sproc as well as any necessary parameters:
using (var db = new BikeStoreEntities())
{
var name = new SqlParameter("@name", DBNull.Value);
var manufacturerCode = new SqlParameter("@manufacturercode", DBNull.Value);
var categoryName = new SqlParameter("@categoryname", DBNull.Value);
var description = new SqlParameter("@description", DBNull.Value);
var features = new SqlParameter("@features", DBNull.Value);
var minListPrice = new SqlParameter("@minListPrice", DBNull.Value);
var maxListPrice = new SqlParameter("@maxListPrice", DBNull.Value);
var statusName = new SqlParameter("@statusName", DBNull.Value);
var manufacturerName = new SqlParameter("@manufacturerName", DBNull.Value);
var models = db.Database.SqlQuery<ModelSelectFilter_Result>("product.ModelSelectFilter @name, @manufacturercode, @categoryname,@description,@features,@minListPrice,@maxListPrice,@statusName, @manufacturerName",
name,manufacturerCode, categoryName, description, features, minListPrice,maxListPrice,statusName,manufacturerName).ToList();
foreach (var model in models)
{
Console.WriteLine(model.ModelId + " | " + model.Name);
}
}
Not a very efficient technique, especially when using a number of parameters. At this point you are simply using EF as a wrapper for ADO.NET, so if this is your main technique, why bother using EF at all?
Conclusion
All in all, sproc access in EDMX is not that bad, and lets us work with entities to a large degree. If your apps are stored procedure-centric, there is a lot of built-in support in Entity Framework that you should find useful.